Bi-Encoder vs Cross-Encoder: When to Use Which
Bi-Encoder vs Cross-Encoder: When to Use Which
A practical guide to choosing the right architecture for semantic similarity
TL;DR
Use bi-encoders for fast retrieval over millions of documents (precompute vectors, index with HNSW). Use cross-encoders for precise reranking of a small candidate set (5-15% better nDCG, but ~1000x slower). The production pattern: bi-encoder retrieves top-K, cross-encoder reranks. Fine-tuned bi-encoders often beat off-the-shelf cross-encoders. Train with sentence-transformers in ~20 lines.
Table of Contents
- The core difference
- Bi-encoder: fast but shallow
- Cross-encoder: slow but precise
- The two-stage pattern
- When to use what
- Practical notes
If you're building anything that compares text (search, matching, ranking, deduplication), you'll hit this decision: bi-encoder or cross-encoder?
Both compute similarity between text pairs. They do it differently, and picking wrong means either painfully slow inference or mediocre accuracy.
I've trained both for production. Here's how I think about it.
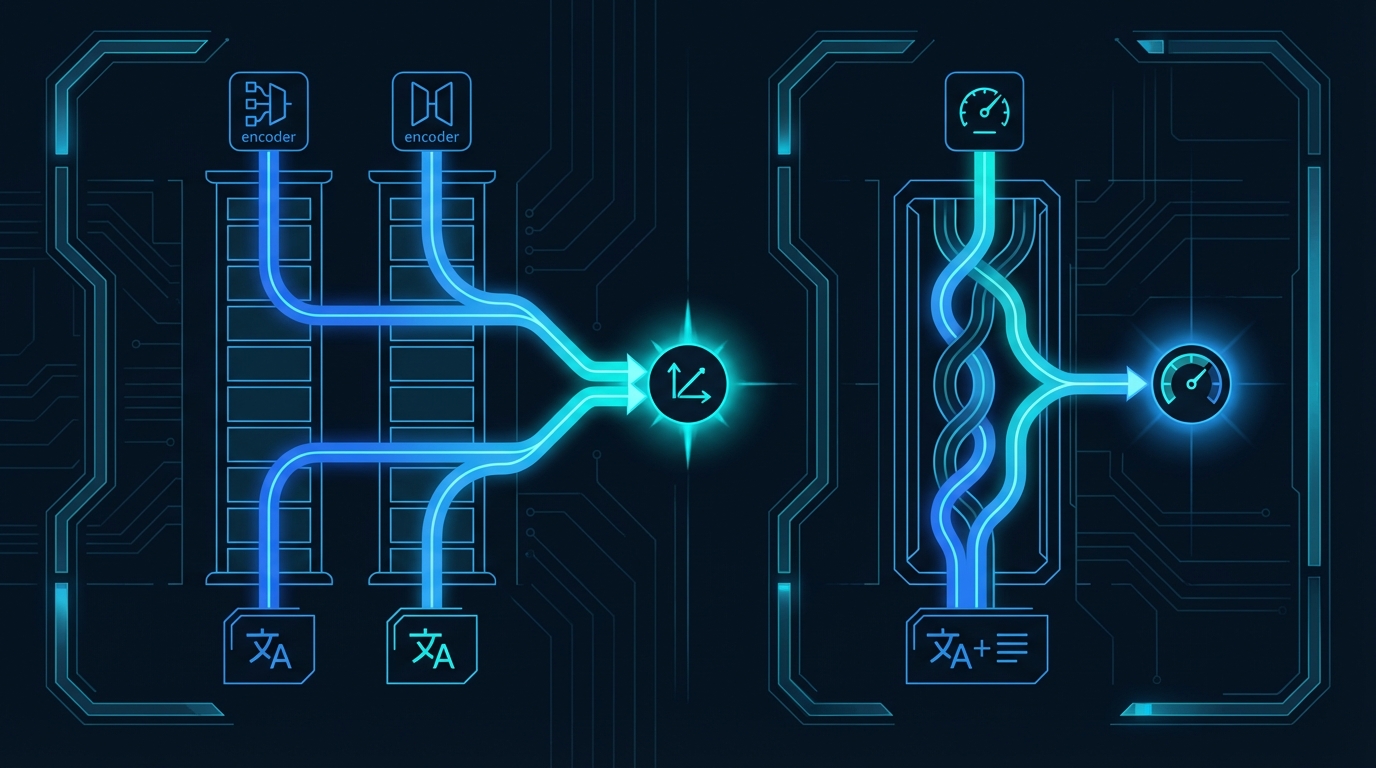
The core difference

A bi-encoder encodes each text independently into a fixed-size vector. You compare vectors with cosine similarity. The texts never see each other during encoding.
A cross-encoder processes both texts together in a single forward pass. The model sees the full context of both texts at once and outputs a relevance score directly.
That one difference determines everything else.
| Feature | Bi-Encoder | Cross-Encoder |
|---|---|---|
| Encoding | Independent per text | Joint (both texts together) |
| Speed | Fast — precompute + dot product | Slow — full forward pass per pair |
| Scalability | Millions of docs via vector DB | Bounded to small candidate sets |
| Accuracy | Good (approximate) | Better (+5-15% nDCG) |
| Use case | Retrieval, search, dedup | Reranking, classification |
| Training data | sentence pairs + scores | sentence pairs + scores |
| Multi-GPU | Scales linearly (DDP) | Supported since v4.0.1 |
| Precomputation | Yes — embed corpus once | No — every pair needs forward pass |
Bi-encoder: fast but shallow
The bi-encoder's advantage is precomputation. Since each text is encoded independently, you can embed your entire corpus once, store the vectors, and compare them at query time with a dot product.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("dwzhu/e5-base-4k")
# Encode everything once
corpus_embeddings = model.encode(corpus_texts)
# At query time, just encode the query
query_embedding = model.encode(query)
# Cosine similarity is a single matrix multiply
scores = cos_sim(query_embedding, corpus_embeddings)
Searching millions of documents? Put the vectors in an HNSW index and get sub-millisecond retrieval. That's what makes bi-encoders usable at scale.
The downside: because the two texts are encoded separately, the model can't attend across them. It doesn't know what the other text says while encoding. For nuanced comparisons, this hurts.
Training
Training a bi-encoder with sentence-transformers is about 20 lines of code:
from sentence_transformers import SentenceTransformer, losses
from sentence_transformers.trainer import SentenceTransformerTrainer
model = SentenceTransformer("dwzhu/e5-base-4k")
train_loss = losses.CosineSimilarityLoss(model)
trainer = SentenceTransformerTrainer(
model=model,
train_dataset=train_data, # needs "sentence1", "sentence2", "score"
loss=train_loss,
)
trainer.train()
For multi-GPU, wrap it with torchrun or accelerate:
torchrun --nproc_per_node=4 train_biencoder.py --batch-size 16 --bf16
DDP handles the rest. Bi-encoders scale linearly across GPUs since each sample is independent.
Cross-encoder: slow but precise
The cross-encoder processes both texts together. Full bidirectional attention between them. The model can compare specific phrases, resolve ambiguities, and catch relationships that bi-encoders miss entirely.
from sentence_transformers.cross_encoder import CrossEncoder
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
# Score a pair — both texts go through the model together
score = model.predict([("query text", "document text")])
On information retrieval benchmarks, cross-encoders beat bi-encoders by 5-15% on nDCG, as demonstrated in the Poly-encoders paper (Humeau et al., 2019) and sentence-transformers cross-encoder benchmarks. In our case, the correlation between predicted and ground truth scores jumped when we switched from bi-encoder to cross-encoder. Not subtly.
The cost: you can't precompute. Every pair needs a full forward pass. Scoring 1,000 candidates against a single query means 1,000 forward passes — roughly 1000x slower than a bi-encoder that encodes the query once and computes dot products against precomputed vectors. It doesn't scale.
Training
Similar setup, different loss:
from sentence_transformers.cross_encoder import CrossEncoder
from sentence_transformers.cross_encoder.losses.BinaryCrossEntropyLoss import BinaryCrossEntropyLoss
model = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2", num_labels=1)
loss = BinaryCrossEntropyLoss(model)
trainer = CrossEncoderTrainer(
model=model,
train_dataset=train_data, # needs "sentence1", "sentence2", "score"
loss=loss,
)
trainer.train()
Multi-GPU support for cross-encoder training landed in sentence-transformers v4.0.1. Before that, you were stuck on a single GPU.
The two-stage pattern
In practice, you don't choose one or the other. You use both.
Query
↓
Bi-Encoder (retrieve top-K from millions) ← fast, approximate
↓
Cross-Encoder (rerank top-K) ← slow, precise
↓
Final ranked results
Stage 1: The bi-encoder retrieves the top 100-500 candidates from the full corpus in milliseconds using vector similarity.
Stage 2: The cross-encoder scores each of those candidates against the query with full attention. 100 forward passes instead of 1 million.
This works because the bi-encoder's recall is good enough (it surfaces the right candidates) and the cross-encoder's precision fixes the ordering. Most production search systems use some version of this.
When to use what
| Use Case | Architecture | Why |
|---|---|---|
| Search over large corpus (100K+) | Bi-encoder + vector DB | You need precomputed embeddings |
| Reranking a shortlist | Cross-encoder | Accuracy matters, size is bounded |
| Real-time similarity | Bi-encoder | Latency requirements |
| Classification/scoring pairs | Cross-encoder | Full attention improves accuracy |
| Deduplication | Bi-encoder | Comparing all pairs is O(n^2) |
| Question answering | Two-stage | Retrieve then rerank |
If your corpus is small (under 10K) and latency is relaxed, just use a cross-encoder. The accuracy gain is worth it.
If your corpus is large or latency matters, go two-stage. More moving parts, but it's the only way to get both speed and accuracy.
Practical notes
I've seen fine-tuned bi-encoders outperform off-the-shelf cross-encoders. Model quality depends more on training data than architecture. Evaluate on your data before committing to either.
Cross-encoders are more memory-hungry per sample because of the longer concatenated sequences. Start with batch size 8 and go up from there. Bi-encoders handle 16-32 per GPU without issues.
Use --bf16 on Ampere+ GPUs. It's faster than FP16 and avoids overflow problems. Both architectures benefit.
Don't skip the evaluator during training. Track EmbeddingSimilarityEvaluator for bi-encoders and CrossEncoderCorrelationEvaluator for cross-encoders. Pearson correlation on your validation set tells you whether training is actually helping.
# Bi-encoder evaluation
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
evaluator = EmbeddingSimilarityEvaluator(
sentences1=val_data["text_a"],
sentences2=val_data["text_b"],
scores=val_data["score"],
main_similarity=SimilarityFunction.COSINE,
)
# Cross-encoder evaluation
from sentence_transformers.cross_encoder.evaluation import CrossEncoderCorrelationEvaluator
evaluator = CrossEncoderCorrelationEvaluator(
sentence_pairs=list(zip(val_data["text_a"], val_data["text_b"])),
scores=val_data["score"],
)

Small corpus, high accuracy needs? Cross-encoder. Large corpus, low latency? Bi-encoder. Most real systems end up using both.

AI Consultant. 9+ years building production AI. Previously Chief Data Scientist at recruitRyte. IIT Dhanbad.